gracehikes.github.io
Examples of Grace Yang’s data science portfolio
================================================================
Project 1: Cluster Visualizations of 60,000 Dating Essay Embeddings
- I first applied Google’s Universal Sentence Encoder algorithm in Colab, a Natural Language Processing (NLP) embedding model, to get 512 embedding dimensions for each dating essay. It is not possible to visualize essay clusters in such high-dimensional data. I used the t-Stochastic Neighbor Embedding (t-SNE) algorithm to represent the high-dimensional data in a space with reduced dimensions.
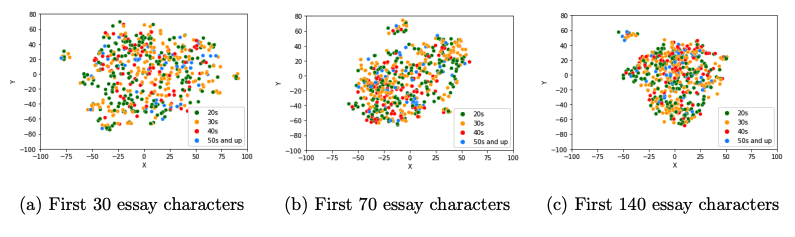
- I performed t-SNE visualizations by age group, gender, pet preferences to check for clear and separate clusters. As essay embeddings became more “watered” down as more text is input into the embedding algorithm, I explored embeddings from various essay lengths: 30 characters (roughly the first four to five words in an essay), 70 characters (first sentence), and 140 characters (first two sentences, or the character count limit for Twitter up through late-2017). There did not appear to be separate clusters observable by age, gender or pet preferences.

================================================================
Project 2: Approximate Nearest Neighbors of Dating Essays
- For popular dating apps and websites like Tinder, Bumble, Match and OKCupid, their customer base ranges between two to eight million people. Match recommendations are not done with brute computation force across all possible pairings or combinations.
- I applied Google’s TensorFlow Hub (TF-Hub) model to dating essays to get high-dimensional embeddings. These embeddings were then used as input for Approximate Nearest Neighbors (ANN) algorithm and generates a ranking of semantic similarities between the text embeddings. This helps to generate app user matches and recommendations very quickly without losing too much accuracy.

================================================================
Project 3: Classification of Dating App User Features
- I used Support Vector Clustering (SVC) to classify the dating essays’ 512-dimensional embeddings generated from Google’s Universal Sentence Encoder module. Can we identify/classify a dating app user’s gender or age group from their essay embeddings using SVC algorithms?
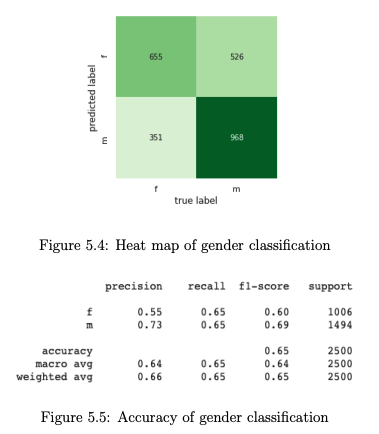
- The classification heat maps and accuracy metrics indicated that the embeddings were somewhat predictive of the gender of the dating app user who wrote the essay: gender prediction accuracy was 65%. Similar explorations by age group did not show good classification accuracies.
================================================================
Project 4: Regression Analysis of Online Screen Time and Teen Mental Health
- I explored the relationship between social media screen time spent and its effect on youth mental health. My causal inference study used a large 2019 survey on 20,000+ households in the U.K. It included questions on how much time the young person spent on social media, computer- and other screen-time (game consoles, computer games, TV) as well as questions on how the child felt about different areas of life.
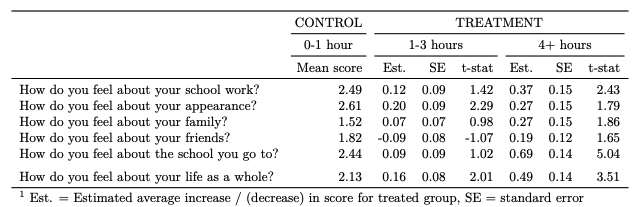
- There appeared to be adverse effects on a young person’s mental well-being when they spent in excess of 4 hours on social media during a normal school day. The measurements came from 6 mental well-being questions and responses from youths aged 10-15 years old in the U.K. survey. While the mental-health effect estimates varied in magnitude for the 6 questions, I found that they were all toward the more unhappy direction of the emoticon scale.

================================================================